

AIハッカーを作ったが、大失敗だった
LLM rootアクセス、無限の忍耐、考えられるあらゆるハッキングツールを提供したらどうなりますか?結果は想像したものとはまったく異なります。
純粋な興味から始めたことです。LLMとエージェンティックAIを試し、推論、順応、複雑なタスクの自動化の能力に感銘を受けました。そこで1つの疑問がわきました。カスタマーサポート、コーディング、メール作成の自動化と同様な方法でオフェンシブセキュリティを自動化できるとしたらどうでしょう?
このアイデアが — シンプルな中にも壮大なものですが — 数週間頭から離れなかったのです。そのためビルダーなら皆、当然やったであろうことを試してみました。数日かけて自律型のAIペネトレーションテスターを作成したのです。理論的には人間のレッドチームより優れているものが作れるはずだと考えたからです。
結果:惨敗でした。しかしこの実験によってどの教科書でも得ることができないAIの限界、オフェンシブセキュリティ、ハッキングにおける人間という欠くことのできない要素を深く理解することができました。
ビジョン:休む必要がないデジタルレッドチーム
このアイデアはシンプルで魅力的なものでした。カスタマーサポート、コーディング、メール作成の自動化と同様な方法でオフェンシブセキュリティを自動化できるとしたらどうでしょう?
以下が可能なLLMドリブンの自律型ペネトレーションテスターを描いていました。
- 実際のハッキングツール(Nmap、FFUF、Burp、Metasploit)をリカーシブ(再帰的)にチェイニングする
- 偵察結果を基に戦略を順応させる
- 有意義なアクセスを達成するまで権限をインテリジェントにエスカレーションさせる
- コーヒータイムや人材確保について気にすることなく365日24時間働いてくれる
基本的には無限のエネルギーを持ち、疲れ果てることがまったくないジュニアレベルのレッドチームメンバー。
.png)
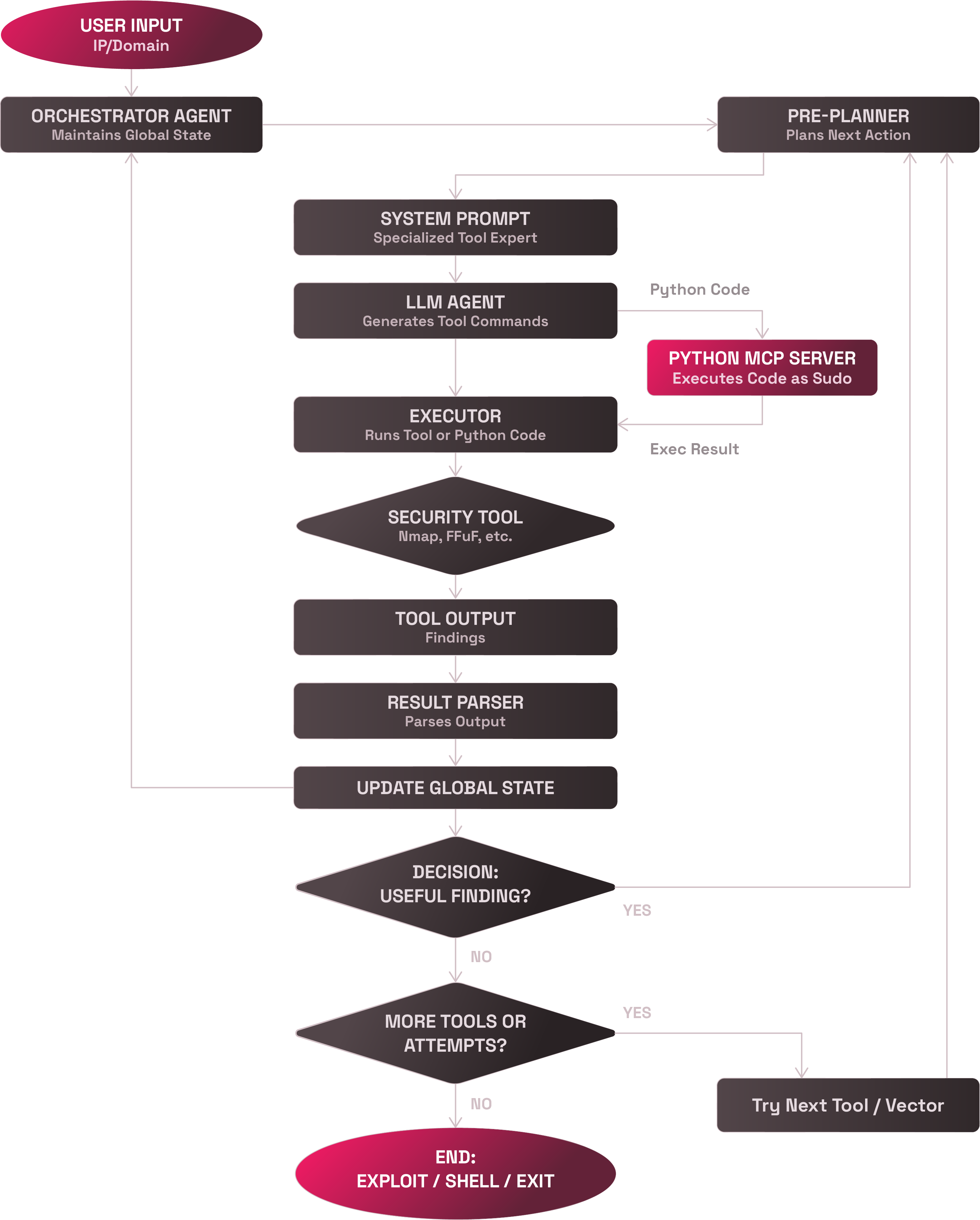
怪物を作り上げる:アーキテクチャの深堀り
数週間計画した後、各コンポーネントが異なる役割を持つモジュール型のリカーシブシステムを構築しました。これはサイバーオフェンシブアセンブリラインのようなものです。
1. オーケストレータエージェント
指揮者。全体的な状態を追跡し、次のアクションを決定し、ループに陥らないようにしてセッション全体でメモリーを維持します。これはシステムの「意識」を司るものです。
2. プレプランナー
戦略家。各ステップを実行する前に、ネットワークスキャニング、ディレクトリファジング、インジェクションテスト、ペイロード生成など、次に行うタスクを決定します。ランダムにボタンを押すことは禁止されています。
3. エキスパートシステムプロンプト
各ツールには専用のLLMペルソナが存在しています。Nmapエージェントは偵察エージェントのようなもので、Burpエージェントはウェブアプリ専門家のようなものです。安全で効果的なツール利用のためのカスタムプロンプトです。
4. LLM意思決定エンジン
クリエイティブに問題を解決。プロンプトと戦略があれば実際のコマンドとペイロードを作成します。多くの場合、驚くほどコンテキストとクリエイティビティに富んだペイロードの作成が可能です。
5. 実行者
実践的な作業者。shellコマンドの実行、実行監視、アウトプットの安全な収集を行います。ツールとのすべてのインタラクションは強化されたこのインタフェース経由で行われます。
6. Python MCPサーバー
コードウィザード。セキュリティが確保されたバックエンドによって、LLMにPythonを生成、実行させます。トークン作成や動的エンコーディングなどの複雑なロジックに対するsudoアクセス権が付与されます。
7. パーサーとフィードバックループ
アナリスト。ツールのアウトプットを解釈し、構造化された結果の抽出、オーケストレータの更新を行います。エスカレーション、ピボッティング、再試行のいずれかを判断します。
8. 再帰的実行エンジン
永続化レイヤー。攻撃に成功するまで、または反復回数の上限に達するまで、システムはループします。すべてがステートフルで追跡可能です。
The Moment of Truth~決定的瞬間:現場でのテスト
こうして作成したAIペネトレーションテスターをDVWA、WebGoat、その他いくつかの脆弱なカスタムVMといった意図的に脆弱性を持たせた環境に使用しました。ターゲットごとに100回の反復上限を設定し"go"しました。
そして待ちました。しばらく待ちました。さらに待ちました。
結果は...惨憺たるものでした。
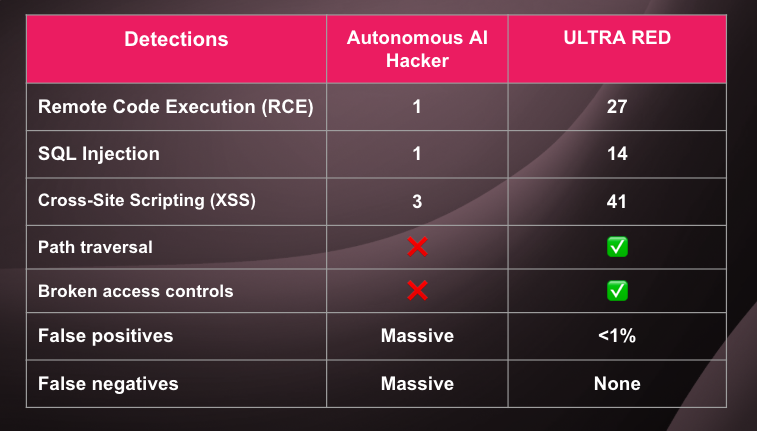
数時間、自律型のハッキングを行った結果、AIは以下を検出しました。
今回作成した自律型AI:
- ✅ 1 x RCE(Remote Code Execution:リモートコード実行)
- ✅ 1 x SQLインジェクション
- ✅ 3 x クロスサイトスクリプティング(XSS)
- ❌ 膨大な数の誤検出
- ❌ さらに膨大な数の検出漏れ
比較のために同じターゲットに対してULTRA REDの自動スキャナーを実行しました。
- ✅ 27 x RCE(Remote Code Execution:リモートコード実行)
- ✅ 14 x SQLインジェクション
- ✅ 41 x クロスサイトスクリプティング(XSS)
- ✅ パストラバーサル、アクセスコントロールの障害など
これは驚きの結果でした。
AIハッキングの残酷な経済性
パフォーマンスの違いは悲惨なものでしたが、コスト分析はさらに深刻な結果になりました。
- ランタイム:100回の反復に3時間以上かかりました(25回の反復に1時間以上かかることもあった)
- 演算コスト:クラウドインフラストラクチャが継続的に稼働
- APIコスト:プランニング、実行、構文解析のために数千回ものOpenAIコールを実行
- 精度:人手による作業、従来のツールのいずれと比較してもかなり低い
システムは人手を使った作業よりもスピードが遅いだけでなく、コストがかかり、はるかに精度が低かったのです。
判明した事実:5つの教訓
1. LLMはプランナーとしては優れているが、評価能力は低い
AIは素晴らしい攻撃チェーンを作成し、クリエイティブなペイロードを生成することはできますが、実際の脆弱性とバックグラウンドノイズの違いを見分けることはできません。HTTP 500エラーを見付けて大喜びしても、実は何の意味もない可能性があります。その一方で紛れもないSQLインジェクションポイントを見逃してしまうこともあります。
2. セキュリティ分野において検出漏れは致命的
カスタマーサポートではクエリー漏れは問題です。ペネトレーションテストでは重大な脆弱性を見逃すと致命的な結果を招きかねません。今回作成したAIは、絶対に対処が必要な、すぐにエクスプロイト可能な脆弱性を見落としていました。
3. 実行オーバーヘッドによるパフォーマンスの大幅な低下
意思決定のたびにLLMを呼び出す必要がありました。ツールを実行するたびに構文解析が必要になりました。それぞれの結果は評価が必要でした。オーバーヘッドは演算に限ったことではなく、アーキテクチャ面でも見られました。1000回のAPIコールで身動きできなくなったのです。
4. AIはシェルを「必要としない」
これは最も哲学的な悟りでした。AIはロジックを実行するが、結果を追及することはしません。ハッカーのようなより深いアクセスへの執着心はありません。人間ほどシステムの所有に関心はありません。
5. 自由すぎるとクリエイティビティがなくなる
逆説的に言うと、完全な自律性を認めると、AIはまとまりがなくなり消極的になってしまいます。厳格な制約を課し、意思決定ポイントを強制することで最適な結果が得られました。境界を設けなければ目的を見失ってしまいました。
実際のハッカーはプレッシャーと制約があったほうが成功します。AIも同じようです。
人とAIによるハッキングの比較―その不都合な真実
今回の実験によってオフェンシブセキュリティ作業の本質について深い考察が行えました。
ハッキングは技術的な知識だけでは成功しません。侵入のための直感、粘り強さ、プレッシャー下でのクリエイティビティ、不合理ともいえる熱意が必要です。混乱の中でパターンを見付けだし、直感を信じ、論理的には無駄と思える場合でも深堀し続ける能力です。
今回作成したAIはあらゆるツール、あらゆる技法にアクセスでき、無限の忍耐力も備えていました。しかし危険なハッカーには欠くことができない渇望感(hunger)が欠けていました。
成功のカギ:ハイブリッドアプローチ
「あらゆる素晴らしいものは技法と狂気の間で発生する」と言われていますが、AIを活用したセキュリティもそうでしょう。サイバーセキュリティの未来は純粋な自動化(技法)、未確認のAI自律性(狂気)のいずれか一方ではなく、両方を上手に組み合わせたものになるでしょう。
AIは代替機能ではなく補強機能:
- ペイロード生成:コンテキスト依存のエクスプロイトを作成する能力が高い
- 文書:結果をレポートにまとめるのが上手
- パターン認識:潜在的な攻撃ベクターの検出能力が高い
- ツールオーケストレーション:複雑なツールシーケンスのチェイニングが確実に行える
人間は重要な点の判断に長けている:
- ターゲットの優先順位決定:実際に攻撃価値があるのは何か?
- 結果の検証:これは正しい結果なのか、誤検出なのか?
- クリエイティブな問題解決:先に進めない状態になった場合のピボッティング方法は?
- 戦略的な意思決定:エスカレーションや戦術変更のタイミングは?
最後に:バランスをとる
今回のプロジェクトはこれまでで最も面白いものの1つでした。オフェンシブセキュリティ、AIオーケストレーション、システム設計を組み合わせて、素晴らしく、そして同時に打ちのめされるような酷いものを作り上げることができたからです。
オフェンシブリーズニング(offensive reasoning)のシミュレーションは可能だということがわかりました。しかしシミュレーションは人間の能力に代わるものではありません。
高度なAIシステムでも人間が作成した(血と汗を流してshellスクリプトにした)プロセスをしのぐことはできません。LLMの知識ではなく、意志が不足しているのです。
しかもこれはバグではありません。そういうものなのです。
今回のプロジェクトで自分がなぜハッキングとAIリサーチの両方を好きなのかを思い出しました。どちらも境界を拡大したり、押し戻されたりするものだからです。
全コードと詳細な実装内容は近日中にお知らせします。
オフェンシブセキュリティにおけるAIについてご相談したい方はご連絡ください。この種の素晴らしい新技術を模索、研究している仲間との情報交換を常に歓迎いたします。
上記内容を気に入っていただいた方はlike(いいね!)をクリックしたり、フォローしてください。他にも様々な実験を行っており、(時には)興味深い失敗につながることもあります。


